Disclaimer:
I am no expert in textual criticism and statistics. I am a chemist by profession and only an amateur textualcritic. I just used available tools and played with the data. This paper is meant as a stimulation for a serious student to explore this field further and deeper. It is my belief that Multivariate Analysis in its many variants is THE TOOL for MSS grouping.
Advice:
What follows are several images with discussion. I would recommend to save these images and print them out separately. They do not fit exactly on the screen.
Update:
I have applied this kind of analysis also to the Text und Textwert collations by the INTF (Münster) of the Gospel of John, ch. 1-10. This analysis can be accessed here.
Principal Component Analysis (PCA) for starters:
When you have collected a large number of variants for a selected number of MSS, each MS has a fingerprint-like pattern of readings. You can now set up a multidimensional space with as many axes as you have variants. Each MS is a point in this multidimensional space. A Principal Component Analysis (PCA) is a mathematical method to "project" this multidimensional space into a 2-dimensional plane. This projection is done in a way that the distances between all points are maximized. Example: Imagine a 3D space and that the points form a cloud that looks like a cigar. This 3D cloud is no projected into 2 dimensions with one axis along the length of the cigar and the other axis orthogonal to it. These two axes are the "principal components".
(Probably a mathematician would cry "Oh no!" but this explanation might nevertheless help to understand the following a little better.)
I used the EXCEL add-on XLSTAT by Thierry Fahmy to perform the PCA's.
I used John 1:1 – 5:11 as a test case, because this is the range of codex Wsup. Several different texttype assignments have been given to this supplementum in the past and initially I wanted to find out were it belongs.
As a data source I used R. Swanson's "NT Greek MSS" and I collected all significant variant readings. A "significant variant reading" is a variant that is not a spelling variant and not a singular reading. From Swanson's data I collected 361 variants. (I also collected all other variants which are about twice as many.)
These variants I divided in "Minority variants" and "Majority variants". A Majority variant is a variant were NA and Maj. divide (I use Maj. for the M-Symbol in NA). Minority variants are variants were NA and Maj. read together against a small group of other MSS.
1. Analysis of the Majority variants:
This analysis mainly separates Byzantine from non-Byzantine MSS. The result of a Principal Component Analysis for John 1:1 – 5:11 is shown here (Please expand your browser to full screen mode):
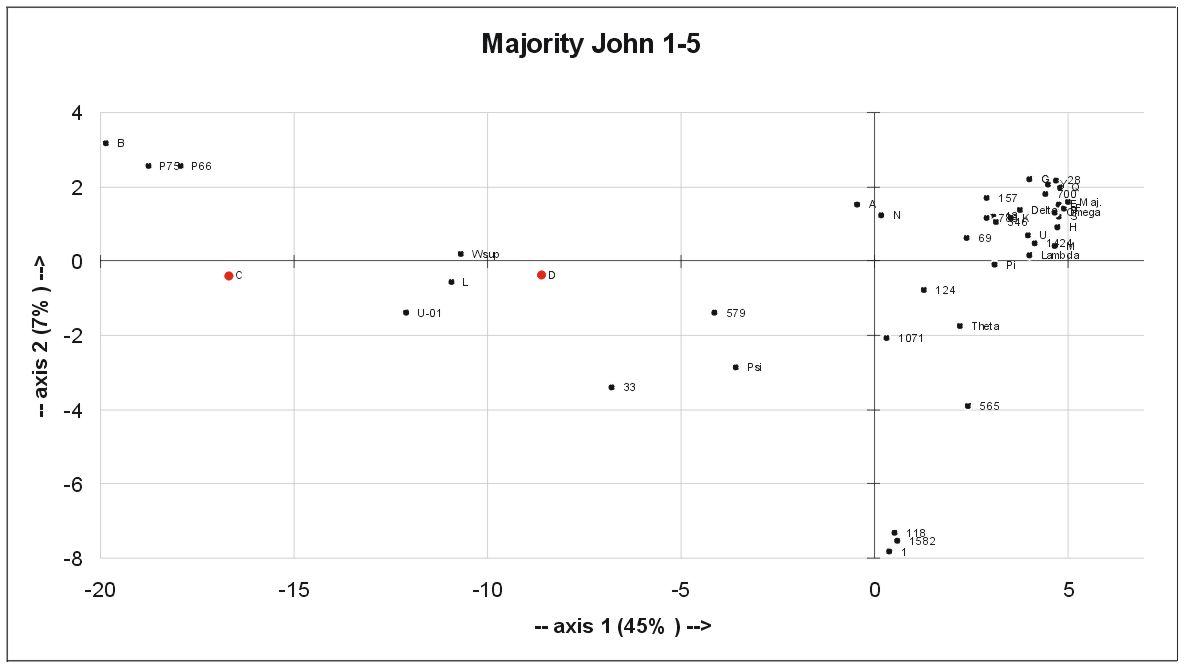
The first question one may ask is: What is represented by the two axes?
The numbers mean nothing to the practitioner. The axes represent the best projection of the multidimensional "MSS-cloud".
The points for C/04 and D/05 are red because these MSS have large lacunae in the selected verse range. Their position is based on a smaller number of data.
The MSS group the way we already know:
1. most left: the pure Alexandrians: P66, P75, B, C
2. middle: the "mixed" Alexandrians: L, Wsup, Psi, 33, 579. 01 and D form the "Western" subgroup of the "mixed" Alexandrians.
3. middle-right: the "early" Byzantines: A, N, Theta, f1, 565, 1071
4. far right: the Byzantine bulk.
It is interesting to note here that the two Western MSS, D and 01 are part of the "mixed" Alexandrians and that the "Caesarean" MSS, Theta, f1, 565 and 1071 are part of the "early Byzantines". Keep in mind that this image shows only the Majority variants. The emphasis is here to separate Alex-kind from Byz-kind MSS.
A closer look can be obtained by separating the data in Alex-MSS alone and Byz-MSS alone. The result is not the same as above because only those variants are utilized that have a separation effect in either of these groups.
The Alex MSS alone:
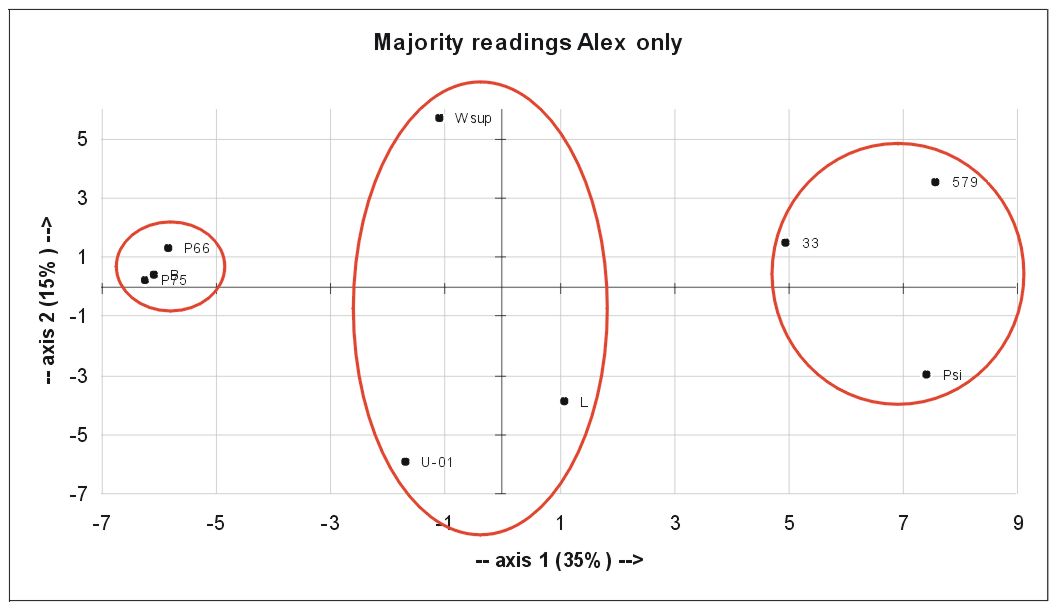
We obtain three groups:
1. P66, P75 and B form a close group: pure Alex
2. Wsup, 01 and L form an intermediate group
3. Psi, 33 and 579 are the low Alex
C (with its reduced number of data) comes between group 1 and 2.
The Byz MSS alone:
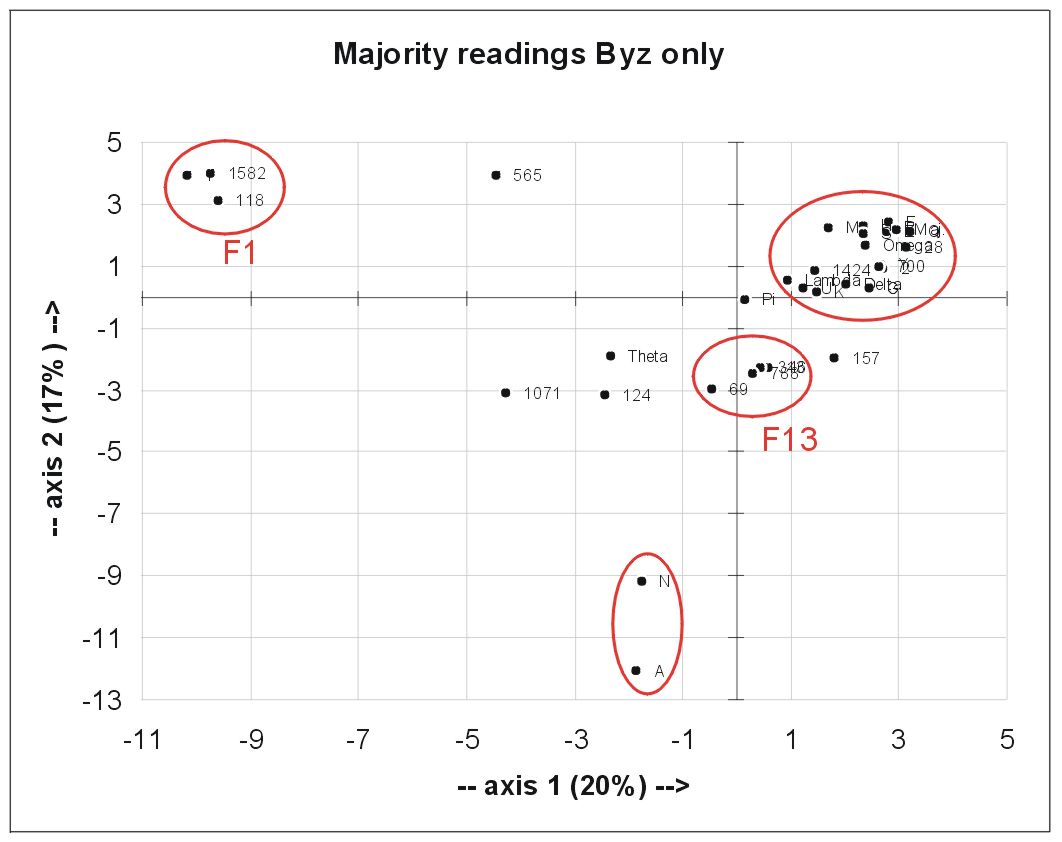
This is also quite interesting because one can see a good separation of several MSS:
1. Family 1, very distinct with the highest number of non-Byz readings.
2. A and N
3. Family 13 quite near the Byz-bulk
4. Sevaral "Caesarean" MSS inbetween
2. Analysis of the Minority variants:
a) All variants in the verse range of D extant:
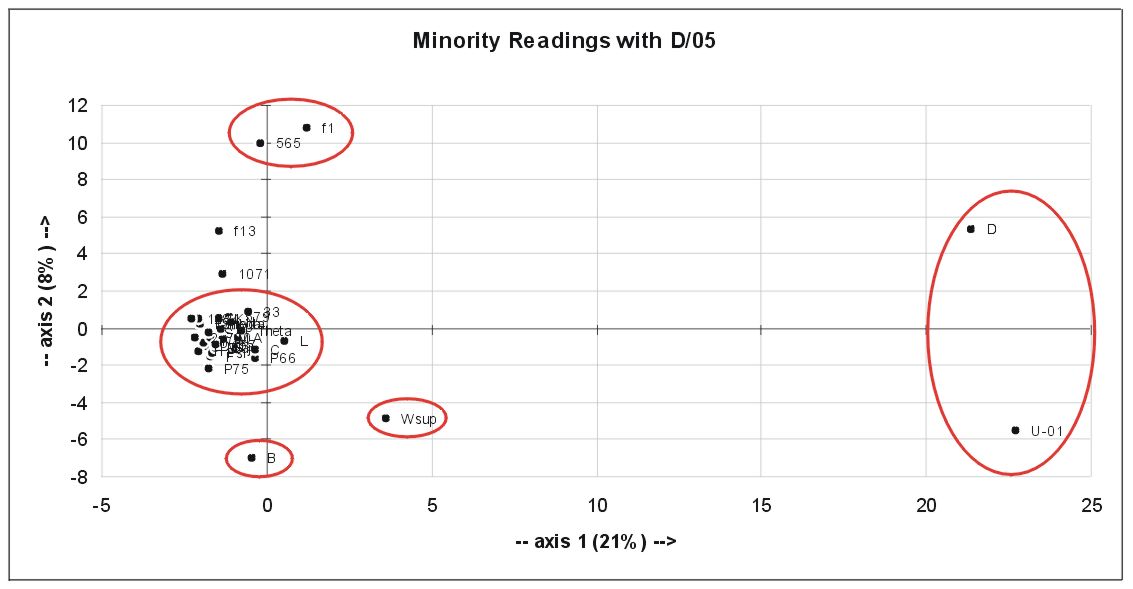
This figure clearly shows that D and 01 forma very distinct group. That 01 is Western in John 1-8 has been found by Boismard (?) and G. Fee already.
Again f1, f13 and 1071 are distinct from the bulk. Since no Majority variants are involved Byz and Alex MSS form the bulk here. Very interesting is the separation of B and Wsup. What does this mean? We come back to this further below.
We can go now a step further and remove D and 01 (the "Western" textform) from the list. Then the figure looks like this:
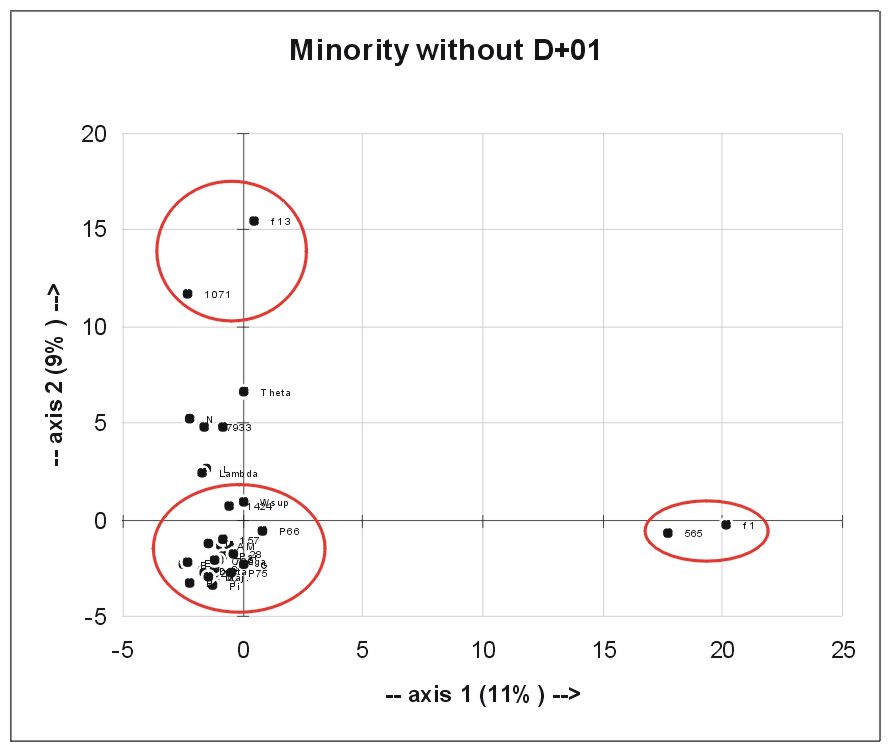
Now f1 and 565 form a very distinct group, also f13 and 1071 form a group. It is possible to call these two groups the "Caesarean" MSS. Theta has no clear relationship with this group.
Note that B and Wsup are not separated from the bulk anymore. This means they are in some way connected with D and 01. For Wsup one would say ok, but B? A close inspection of the variants involved shows that the significant agreements are with 01 alone and not with D. Also they do not agree all three together, only B/01 or Wsup/01. It is my opinion that these "agreements" with 01 are due to the fact of carelessness errors. It is clear from the many singular readings of Wsup and 01 that these are simply slips of the pen and/or memory. So one could say 01, B and Wsup share some carelessness-errors (with B only mild and Wsup/01 more wild). [This part of of this paper is the most speculative and I would like to hear what others think!]
We can go even further into the details and look at all Minority variants that are not influenced by D, 01, f1, f13, 565 and 1071 (Western and Caesarean):
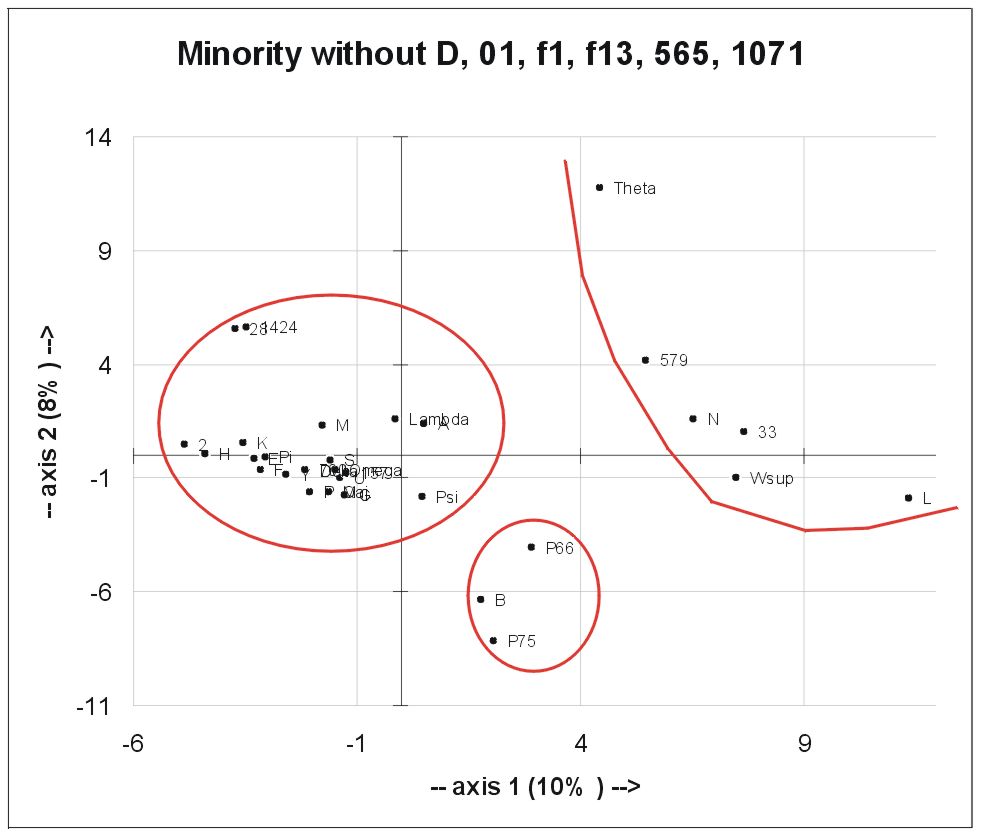
Here the Byz MSS form the bulk. P66, P75 and B form again a close group. L, N, Theta, Wsup, 33 and 579 are clearly separated from these two groups. it is interesting how clearly N stands out of the Byz bulk here.
Another subgroup: The Minority variants in the subgroup of the Byz MSS only:
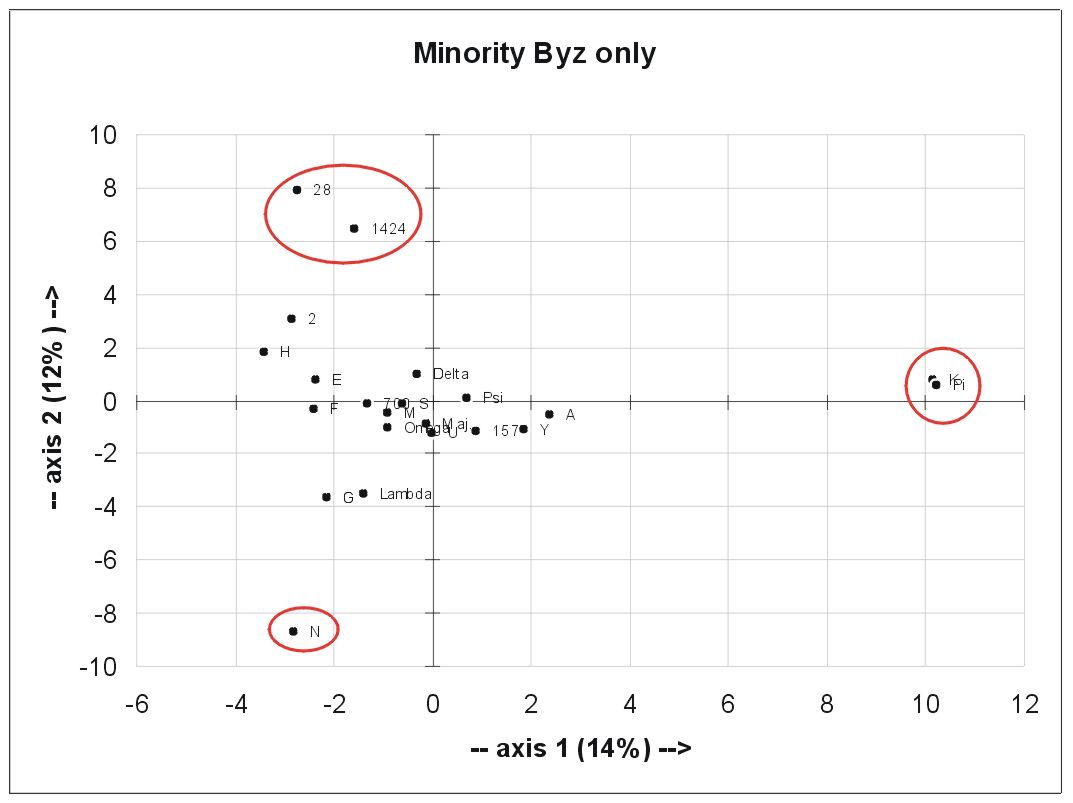
Very interesting that Family Pi (K and Pi) stands out here clearly. Also interesting that A is its next neighbour. The only other MSS that are separated from the bulk are 28 and 1424.
Summary:
PCA is a good method to analyse MSS relationships. For the test-case John 1:1-5:11 the following results have been obtained:
1. These MSS can be considered as basically Alexandrian:
P66, P75, B, C, L, Wsup, Psi, 33, 579
2. The western subgroup: 01 and D
3. All other MSS are basically Byzantine, with A, N, f1 and 1071 to be the most non-Byzantine of these.
4. A more detailed analysis separates f1, f13, 565 and 1071 as a fourth group of MSS which we can call "Caesarean". Here f1 and 565 form a close subgroup and f13 and 1071 form another subgroup. Theta is not very distinct and should be considered Byzantine.
5. In the group of the Byzantine MSS Family Pi clearly stands out and also A and N. Looking at A and N and their difference from the Byzantine bulk, this is mainly caused by a higher number of Alex readings. They might be called "pre-Byz".
6. In the group of the Alexandrian MSS the following subgroups can be distinguished:
a) P75 and B
b) P66 and C
c) Wsup, L, (01, D)
d) 33, 579, (Psi)
The group c) is the less distinct. In a close inspection Wsup tends more to P66, whereas L tends more to 33.
This also answers the initial question about the textual character of Wsup: Wsup is characterized by a large number of singular readings and carelessness errors. This is probably due to the fact that it is only a supplement for an existing codex (fast and careless copying). The texttype is Alexandrian with slight Byzantine mixture. Probably his exemplar was similar to P66 or C or slightly more Byzantine.
A short look at the spelling variants (section A in Swanson) shows that Wsup has an enormous amount of itacisms together with 01, P66 and N. Most of these itacisms are I <----> EI variants. Wsup alone is prone to interchange E <----> AI.
It is also interesting to mention that Wsup agrees constantly with P66, P75, B and C alone (the hardcore Alexandrians) in using Aorist-1 endings for Aorist-2 (EIPAN/EIPON variants). Surprisingly these variants are the best separator of hard and weak Alexandrians.
One last thing: Up to now we always looked at the MSS. It is also possible with PCA to look at the variants. We can change rows and columns and look how the variants behave. This has also been suggested by Timothy Finney in his thesis. The result is interesting because it singles out variants that are special in some way. This is interesting for example for the Münster group to find some exposed variants for their "Teststellen" system.
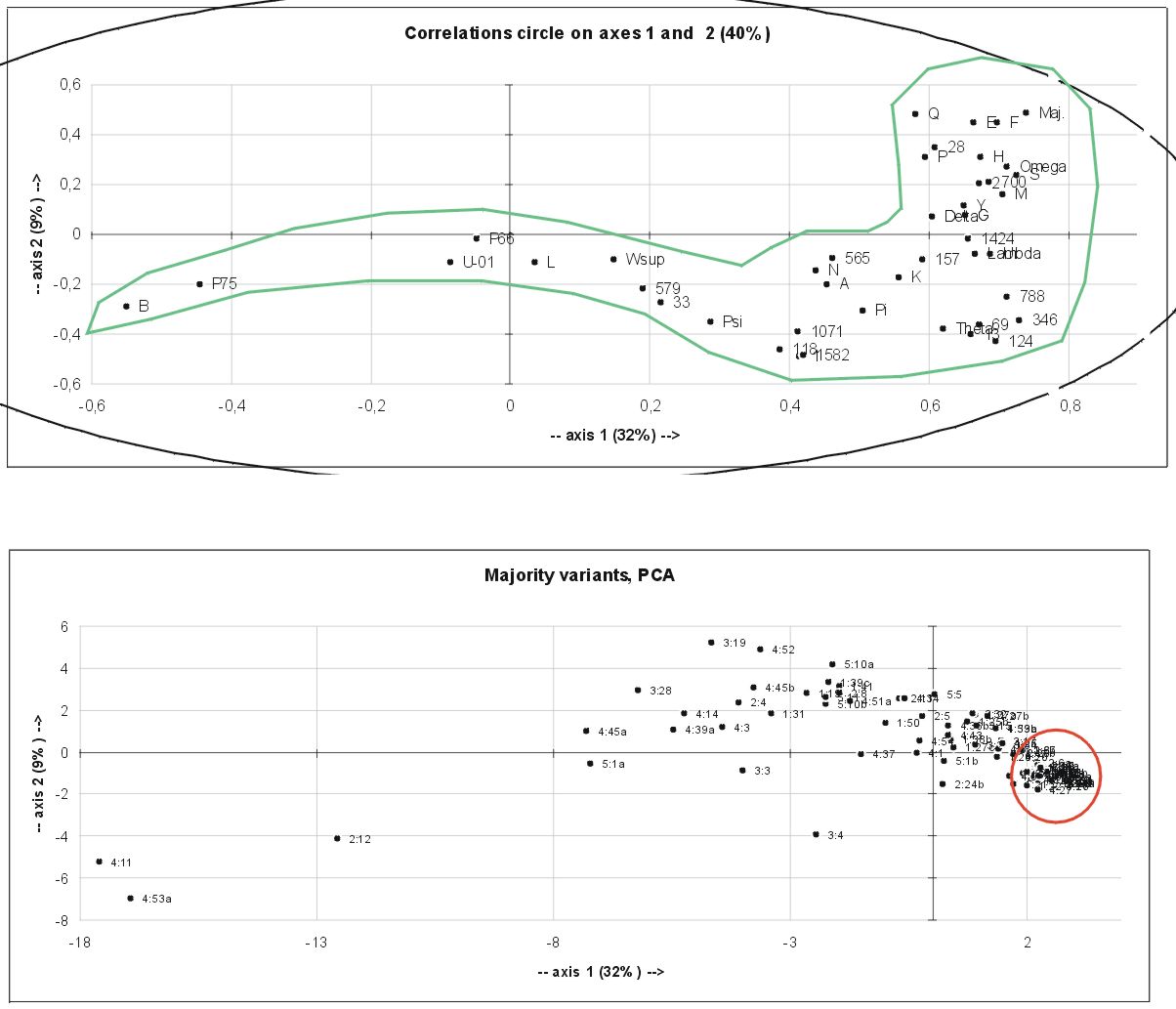
This image (bottom) shows just as an example a PCA of the Majority variants. The more strange the grouping of witnesses is the more to the left the verses appear. E.g. verse 2:12 the famous OI ADELFOI AUTOU, which has:
omit AUTOU (P66*, P75, B, K, L, Pi, Psi, 0162, f13, 28, 579, 1071)
That means most hardcore Alexandrians read against NA.
The large majority of variants has more or less the same witness pattern. These verses group in the encircled bulk.
One can look at the corresponding correlation circle (top), which shows the influence of the individual witnesses on the PCA of the verses.
Maybe I can enter TC eternity by coining the term "Willker-pipe" for this correlation? Give me a chance! :-)
This image gives the intriguing (but of course wrong) impression as if it visualizes the stream of MSS transmission over time and that the autograph can be found somewhere left from B.
Ok, that's it. I hope you have enjoyed this presentation and are stimulated enough to try this out on your own or by joining with a mathematician.
What I have shown here is only the tip of the iceberg.
What I haven't done yet, but what has to follow now is the study of the various variants in every detail, what they are and how they influence the PCA's. Lot of work...
Continue to the PCA analysis of the T&T collations ...